Dataloader의 필요성
파이토치 튜톨리얼을 따라하면서 딥러닝을 배우다보면 기본적으로 데이터 셋이 모두 준비되어있어 따라하기만 하면 학습을 진행 할 수 있다. 하지만 우리가 딥러닝을 배우고자 했던 목표는 자신의 이미지를 가지고 학습 시켜 자신의 프로젝트를 진행하는 거였을꺼다. 이를 위해서 알아야 하는게 dataloader다.
이 포스트에서는 pytorch cifar10 튜톨리얼을 응용해서 직접 cifar10 데이터를 로드하고, 학습시켜 본다.
대략적인 구조
우리가 학습하고자 하는 데이터 셋에 대해 Dataset 클래스로 정의한뒤, Dataloader 클래스에 인수로 주면 network에서 우리의 데이터를 사용할 수 있다. 간단하게 Dataset 클래스와 Dataloader에 대해 알아보자.
Dataset
데이터셋에는 학습할 데이터의 경로를 정의하고, 데이터를 경로에서 읽어 리턴한다. 데이터셋의 크기가 클 수 있으므로, __init__에서 전체 데이터 읽어오는 것이 아니라 경로만 저장해놓고, __getitem__ 메소드에서 경로에서 이미지를 읽어 반환하게 만드는게 효율적일 것이다.
Dataset 클래스가 가져야할 가장 기본적인 구조는 다음과 같다.
class MyDataSet(Dataset):
def __init__(self):
# 인자를 받아 인스턴스 변수를 초기화
def __len__(self):
# 데이터 셋의 길이를 리턴한다.
return len()
def __getitem__(self):
# 학습 이미지와 이미지의 GT (cifar10이므로 이미지의 class)를 리턴한다.
return traning_data, ground_truth
Dataset은 크게 3가지 메소드를 정의한다.
__init__
일반적인 클래스에서의 사용법과 동일하다. 클래스에서 사용할 인자를 받아 인스턴스 변수로 저장하는 일을 한다. 예를들면, 이미지의 경로 리스트를 저장하는 일을 하게 된다.
__len__
데이터 셋의 길이를 정수로 반환한다. cifar10의 경우 트레이닝, 혹은 테스트 셋의 전체 이미지의 갯수가 될 것이다.
__getitem__
실제 이미지 파일과 해당이미지의 GT(ground truth) 값을 반환한다. cifar10의 경우 이미지 배열과 해당이미지가 고양이인지, 배인지, 사슴인지 등을 담은 class를 리턴하게 된다.
Dataloader
pytorch 문서에서 torch.utils.data.DataLoader를 찾아보면 다음과 같이 나온다.
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
당장 필요한것만 설명하면 다음과 같다.
- dataset : 데이터에 대해 명세한 dataset 클래스 객체를 넣으면 된다.
- batch_size : 배치 사이즈는 minibatch를 말한다. 그래픽카드의 메모리에 따라 적절한 값을 지정한다. 클수록 메모리에 한번에 많은 이미지를 올려 학습시키기 때문에 학습 속도가 빨라진다. 하지만 이번엔 4 정도로 할것이다.
cifar 10 이미지 파일 가져오기
cifar 10 image
어떤 착한분이 이미지 파일로 만든 cifar-10을 깃허브에 올려놓으셨다.
- https://github.com/YoongiKim/CIFAR-10-images
이걸 clone 해서 사용하기로 한다.
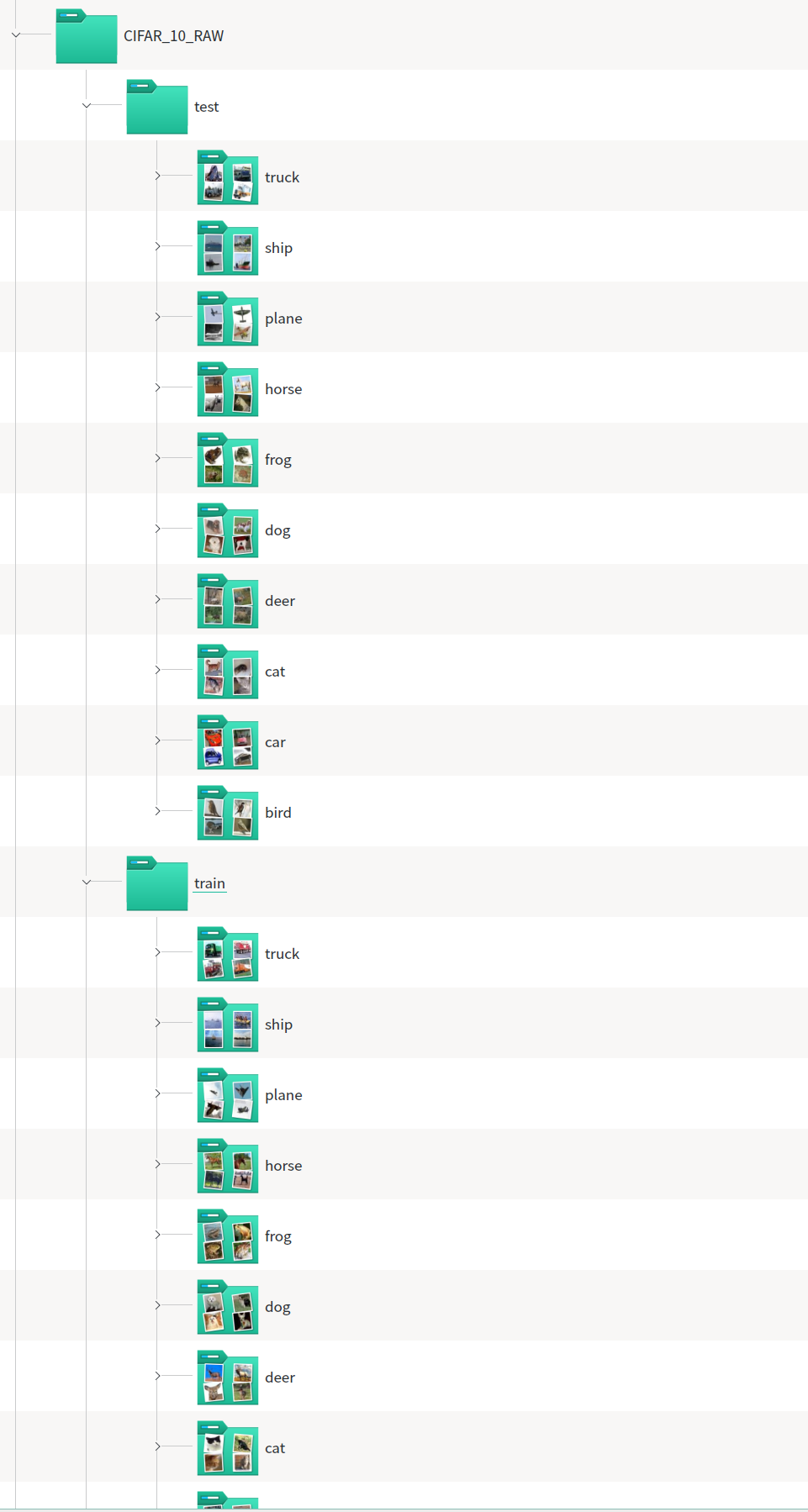
파일을 확인해보면, train, test 폴더 내부에 각각의 클래스 이름이 있고, 그 내부에는 해당 클래스의 이미지들이 jpeg 파일로 저장되어있다. 폴더의 이름을 클래스로 사용할 생각인데, pytorch 튜톨리얼과 클래스 이름을 맞춰주기 위해 디렉토리의 이름을 airplane을 plane으로, automobile을 car로 변경하였다.
glob
cifar 10 이미지 파일의 경로를 가져와 리스트에 저장하기위해 glob 함수를 사용한다. glob 함수는 주어진 경로를 만족하는 파일을 불러와 리스트로 반환한다. *(아스타리스크)를 이용하면 모든 문자열에 매치되어 모든 파일을 가져오게 된다.
from glob import glob
DATA_PATH_TRAINING_LIST = glob('./CIFAR_10_RAW/train/*/*.jpg')
DATA_PATH_TESTING_LIST = glob('./CIFAR_10_RAW/test/*/*.jpg')
Dataset 정의하기
이제, 데이터셋을 정의하여야 한다. 먼저, Dataset을 상속하여 클래스를 만든다. 그뒤 위에서 설명한 몇개의 함수를 정의하여야 한다.
from torch.utils.data import Dataset, DataLoader
from skimage import io, transform
class MyCifarSet(Dataset):
__init__
생성자인 __init__ 을 정의한다. cifar 10 이미지의 path 리스트와, 클래스 명, transform을 받기로 하였다.
def __init__(self, data_path_list, classes, transform=None):
self.path_list = data_path_list
self.label = get_label(data_path_list)
self.transform = transform
self.classes = classes
__len__
전체 데이터 셋의 길이를 반환하여 주면 된다. 생성자에서 정의한 path_list 의 길이를 반환하자.
def __len__(self):
return len(self.path_list)
__getitem__
학습에 사용할 이미지를 반환하면 된다. 이 함수는 인풋으로 index를 받는다. path_list에서 index에 해당하는 이미지를 읽으면 된다. 이때 텐서형태의 인풋이 들어오기때문에 리스트로 변환하여준다.
반환값으로는 경로로부터 읽어들여 transfome을 적용한 이미지 파일과 정답에 해당하는 클래스를 반환하면 된다. 이때, 클래스를 숫자로 반환하여야 한다. 예를들면 차는 0, 고양이는 1, 개는 2 와 같은식이다. 클래스 리스트의 index로 반환하게 구현하였다.
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
image = io.imread(self.path_list[idx])
if self.transform is not None:
image = self.transform(image)
return image, self.classes.index(self.label[idx])
get_label
앞서 학습에서 경로의 폴더명을 class로 이용할 예정이라고 했다. 위의 getitem을 보면, label로 부터 class를 얻는것을 확인 할 수 있다. 이를 구하기 위한 get_label 함수를 정의하자. data_path_list의 각 이미지에 대한 class를 저장한 리스트를 반환하면 된다. 각 path의 뒤에서 첫번째자리는 이미지 파일의 이름이고, 두번째 자리가 class이므로 이값을 저장한다.
def get_label(data_path_list):
label_list = []
for path in data_path_list:
# 뒤에서 두번째가 class다.
label_list.append(path.split('/')[-2])
return label_list
완성된 데이터셋 코드
from torch.utils.data import Dataset, DataLoader
from skimage import io, transform
class MyCifarSet(Dataset):
#data_path_list - 이미지 path 전체 리스트
#label - 이미지 ground truth
def __init__(self, data_path_list, classes, transform=None):
self.path_list = data_path_list
self.label = get_label(data_path_list)
self.transform = transform
self.classes = classes
def get_label(data_path_list):
label_list = []
for path in data_path_list:
# 뒤에서 두번째가 class다.
label_list.append(path.split('/')[-2])
return label_list
def __len__(self):
return len(self.path_list)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
image = io.imread(self.path_list[idx])
if self.transform is not None:
image = self.transform(image)
return image, self.classes.index(self.label[idx])
Dataloader
데이터 로더를 세팅하는건 매우 간단하다. 첫번째 인자에 앞서 만든 데이터셋 클래스를 넣고, batch_size를 설정하면 된다.
#own dataset
trainloader = torch.utils.data.DataLoader(
MyCifarSet(
DATA_PATH_TRAINING_LIST,
classes,
transform=transform
),
batch_size=4,
shuffle = True
)
testloader = torch.utils.data.DataLoader(
MyCifarSet(
DATA_PATH_TESTING_LIST,
classes,
transform=transform
),
batch_size=4,
shuffle = False
)
튜톨리얼 코드 데이터 로더 대체하기
이젠 정말로 이미지로부터 데이터를 불러와 보자. pytorch의 cifar10 tutorial을 보면 다음과 같은 코드가 있다.
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
이를 위에서 만든 코드로 대체하면 아래와 같다.
from torch.utils.data import Dataset, DataLoader
from skimage import io, transform
from glob import glob
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
class MyCifarSet(Dataset):
#data_path_list - 이미지 path 전체 리스트
#label - 이미지 ground truth
def __init__(self, data_path_list, classes, transform=None):
self.path_list = data_path_list
self.label = get_label(data_path_list)
self.transform = transform
self.classes = classes
def get_label(data_path_list):
label_list = []
for path in data_path_list:
# 뒤에서 두번째가 class다.
label_list.append(path.split('/')[-2])
return label_list
def __len__(self):
return len(self.path_list)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
image = io.imread(self.path_list[idx])
if self.transform is not None:
image = self.transform(image)
return image, self.classes.index(self.label[idx])
DATA_PATH_TRAINING_LIST = glob('./CIFAR_10_RAW/train/*/*.jpg')
DATA_PATH_TESTING_LIST = glob('./CIFAR_10_RAW/test/*/*.jpg')
trainloader = torch.utils.data.DataLoader(
MyCifarSet(
DATA_PATH_TRAINING_LIST,
classes,
transform=transform
),
batch_size=4,
shuffle = True
)
testloader = torch.utils.data.DataLoader(
MyCifarSet(
DATA_PATH_TESTING_LIST,
classes,
transform=transform
),
batch_size=4,
shuffle = False
)
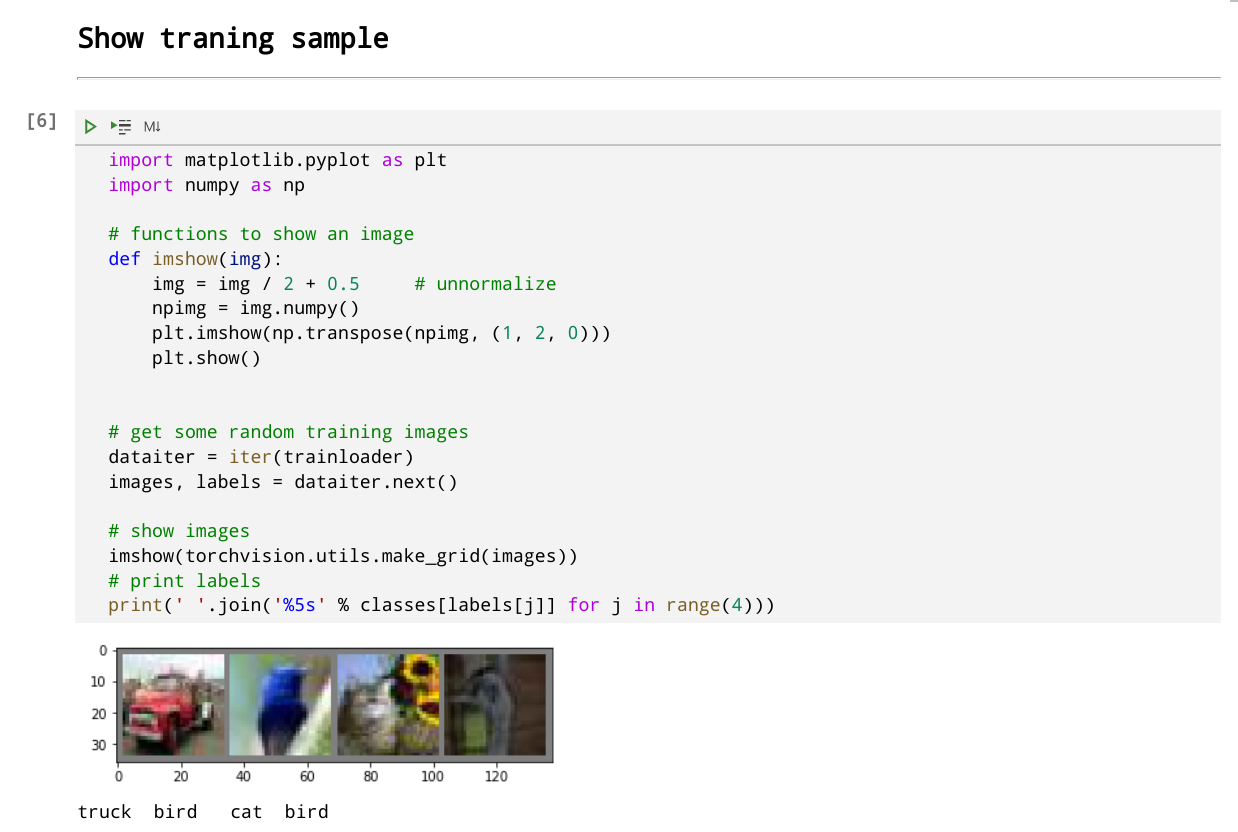
이제 실행해보면 이미지를 잘 불러오는걸 볼 수 있다.